本程序是一款基于Python开发的网站爬虫工具,具备直观的图形化用户界面。用户可轻松地输入目标网站和相关参数,启动爬虫,并实时查看爬取日志。程序能够递归地爬取指定网站的所有链接,并将其保存为 Sitemap 文件,方便进行网站的 SEO 优化。
功能介绍
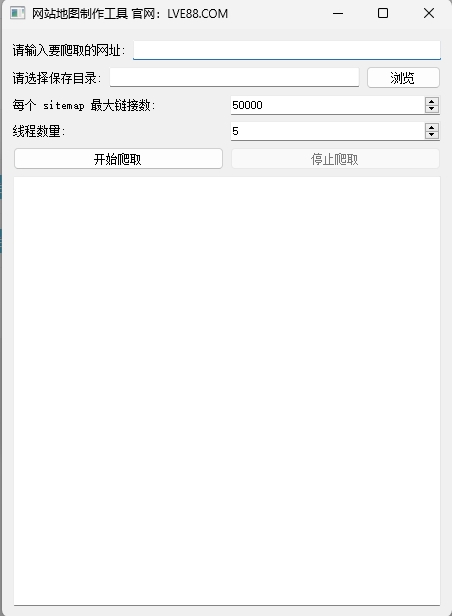
图形化用户界面(GUI)
程序界面直观易用,提供友好的布局设计,用户可以轻松输入参数并进行操作。在界面上,还能实时查看爬取过程中的日志信息,便于随时跟踪爬取进度和状态。
多线程爬虫
支持多线程并发爬取,极大提升了爬取效率。用户可以根据自身需求自定义线程数量,以便在速度与资源消耗之间找到最佳平衡。
Sitemap 文件生成
程序生成符合搜索引擎标准的 XML 格式 Sitemap 文件,保证文件格式标准化。并且,用户可以根据设定控制每个 Sitemap 文件中链接的数量,避免单个文件过大,方便管理。
链接过滤
程序会自动过滤带有查询参数的链接,防止不必要的页面(如搜索结果页)被爬取。如果有特殊需求,用户也可以调整过滤规则,自定义过滤特定的 URL 模式或参数。
保存目录管理
用户可以灵活设置 Sitemap 文件的保存位置。程序会在用户设定的保存目录下自动创建以爬取域名为名称的子目录,便于对多个站点的文件进行分类管理。
停止爬取功能
用户可以随时通过界面上的“停止爬取”按钮即时停止爬取过程,确保操作安全。在停止爬取后,程序会自动保存已经获取的链接,防止数据丢失。
错误处理和编码支持
程序内置完善的错误处理机制,确保即使在异常情况下也能稳定运行,不会因个别问题导致整个程序崩溃。同时,程序具备多语言支持,能够正确处理包含中文等多语言字符的链接和网页内容,避免出现乱码问题。